

 Top Rated Course
Top Rated Course

We may not have the course you’re looking for. If you enquire or give us a call on 01344203999 and speak to our training experts, we may still be able to help with your training requirements.
Top 30 Hadoop Interview Questions and Answers
Eliza Taylor 18 November 2024Explore the world of big data with our comprehensive blog on Hadoop Interview Questions and Answers. Whether you're an aspiring data engineer or an experienced professional, this blog provides valuable insights into the most commonly asked Hadoop interview questions and expertly crafted answers. Master your Hadoop interviews with our in-depth resource.
Training Outcomes Within Your Budget!
We ensure quality, budget-alignment, and timely delivery by our expert instructors.
Table of Contents
Related Courses

Preparing for a job in the big data industry requires a solid understanding of Hadoop, one of its cornerstone technologies. This is why Hadoop Interview Questions are an essential part of the hiring process for roles ranging from development to administration within the Hadoop ecosystem.
According to ITJobsWatch, the average median salary of a Hadoop expert is around £75,000. Read this blog to learn about the top 30 Hadoop Interview Questions and answers categorised into Basic, Intermediate, and Advanced categories.
Table of Contents
1) Basic Hadoop Interview Questions
2) Intermediate Hadoop Interview Questions
3) Advanced Big Data Hadoop Interview Questions
4) Tips for acing your Hadoop interview
5) Conclusion
Basic Hadoop Interview Questions
Here are some basic Hadoop Interview Questions and answers that will help you in your interview:

Basic Hadoop Interview Questions
Here are some basic Hadoop Interview Questions and answers that will help you in your interview:
What is Hadoop?
Answer: Hadoop is an open-source framework developed by the Apache Software Foundation. It is designed for distributed storage and processing vast amounts of data using a network of commodity hardware. The primary motivation behind creating it was to handle petabytes and exabytes of data efficiently.
Why is Hadoop important for Big Data?
Answer: Hadoop is important for Big Data because it has revolutionised how organisations process and store big data. Its distributed storage system, Hadoop Distributed File System (HDFS), allows data to be stored reliably across many machines, ensuring fault tolerance.
Additionally, its processing model, MapReduce, enables parallel processing of vast datasets. As a result, tasks that once took days can now be completed in hours. This scalability, cost-efficiency, and reliability make it indispensable for Big Data challenges.
Explain the core components of Hadoop.
Answer: Hadoop primarily consists of two core components:
a) HDFS: It represents the storage unit of Hadoop. It divides large files into blocks (typically 128MB or 256MB). It stores multiple copies of these blocks across the cluster to ensure fault tolerance.
b) MapReduce: It is Hadoop's processing unit. It allows data to be processed in parallel using a distributed algorithm. The process is split into two phases: the Mapper and Reducer phase. In Mapper phase, inputted data is processed, and output is produced as key-value pairs. In the second phase, these key-value pairs are aggregated to generate the desired output.
What is the difference between structured and unstructured data and how does Hadoop help with them?

Answer: Structured data is organised into rows and columns. It is usually in Relational Databases. Examples include data from Excel sheets or SQL databases. Unstructured data, however, doesn’t have a specific format or structure, like texts, images, or social media posts.
Hadoop is incredibly versatile in dealing with both. While traditional databases are efficient for structured data, it struggles in volume and variety. Hadoop's HDFS can store varied data types, be it structured, semi-structured, or unstructured, making it ideal for big data scenarios.
Describe the role of a NameNode in Hadoop.
Answer: In HDFS, the NameNode is the master server that is responsible for managing the file system namespace and regulating access to files by clients. It keeps the directory tree of all files in the file system. Along with that, it also tracks the files across the cluster. However, the actual data isn’t stored in the NameNode but in DataNodes. Should the NameNode fail, the entire Hadoop system can become inoperable, underscoring its criticality.
How does Hadoop achieve fault tolerance?
Answer: Fault tolerance in Hadoop is achieved primarily through data replication. When data is fed into the system, HDFS divides it into blocks and creates multiple replicas of each block across different nodes in the cluster. By default, it makes three copies of each block. If a node or a few blocks fail, data can still be retrieved from the other block replicas, ensuring data is never lost.
Are you looking to advance your career in the rapidly growing field of Big Data? Don't miss your chance to become an industry expert with our Hadoop Big Data Certification course!
What is the significance of the DataNode in Hadoop architecture?
Answer: DataNode, often termed a slave, performs the actual storage and retrieval tasks in HDFS. Each DataNode sends a heartbeat signal to the NameNode, signifying its presence and operational status. They store and manage the data blocks and, upon instruction from the NameNode, perform block creation, deletion, and replication tasks.
Can you explain the role of the JobTracker and TaskTracker in Hadoop?
Answer: While these components are more associated with older versions of Hadoop, they are fundamental in understanding Hadoop's processing model:
a) JobTracker: Acts as the master daemon in the MapReduce processing paradigm. It receives processing requests, schedules jobs, and allocates tasks to specific nodes.
b) TaskTracker: This is the slave daemon. TaskTrackers run the tasks as the JobTracker directs and continuously communicate with the JobTracker, sending heartbeat signals and task status reports.
How is Hadoop different from Traditional Databases?
Answer: Traditional Databases, like Relational Database Management Systems (RDBMS), are designed for structured data and use schemas to define data types. They are not optimised for handling vast volumes of unstructured or semi-structured data. Hadoop, in contrast, is built for vast datasets, irrespective of their structure. Its distributed file system allows it to store and process data across multiple nodes in a cluster, ensuring scalability, fault tolerance, and high data processing speed.
Can you explain what a Block is in HDFS?
Answer: A block is the minimum unit of storage in HDFS. By default, the block size is 128 MB, much larger than those in traditional filesystems. Large block sizes offer advantages like reduced metadata storage and faster data processing.
Gain knowledge on how to install Impala with our Hadoop Training Course with Impala .
Intermediate Hadoop Interview Questions
In this section, you will learn the most asked intermediate Hadoop Interview Questions. Here they are:
In this section, you will learn the most asked intermediate Hadoop Interview Questions. Here they are:
Answer: It uses the HDFS to distribute data across multiple nodes. Data is split into fixed-size blocks (usually 128MB or 256MB). These blocks are distributed across the cluster nodes. Redundant copies of each block are stored on different nodes to ensure data durability and fault tolerance. This distributed approach allows for parallel processing and storage, making Hadoop especially effective for handling massive datasets.
Explain the concept of MapReduce with a simple example.
Answer: MapReduce is a programming model Hadoop uses for processing large datasets in parallel. It comprises two main steps:
a) Map: Breaks down the task into key-value pairs.
b) Reduce: Processes these pairs to produce a smaller set of aggregated key-value results.
For instance, consider counting the occurrence of words in a text. The Map phase would break down the text into words and assign a value of '1' to each word. The Reduce phase then aggregates these values for each unique word, producing a count for every word.
What is YARN, and how has it improved Hadoop?
Answer: Yet Another Resource Negotiator (YARN) is a resource management layer for Hadoop. Introduced in Hadoop version 2.x, YARN decouples the programming model from the resource management. This allows for multiple data processing engines. It consists of a Resource Manager, Node Managers, and Application Masters. YARN's introduction enhanced Hadoop's scalability, multi-tenancy, and performance, making it more versatile for varied processing tasks beyond just MapReduce.
Discuss the significance of the Hadoop Combiner.
Answer: The Combiner in Hadoop is a mini reducer during the Map phase. Its primary purpose is to process the local output of the Map task before it's sent to the Reduce phase. Doing this reduces the amount of data sent to the Reducer. It also optimises data processing and network bandwidth. However, it's important to note that not all tasks suit a Combiner. Its use must make sense for the specific operation being performed.
Ready to level up your career in Big Data? Join our Hadoop Administration Training today to gain hands-on expertise in managing large data clusters.
Describe the differences between Hadoop 1.x and Hadoop 2.x.
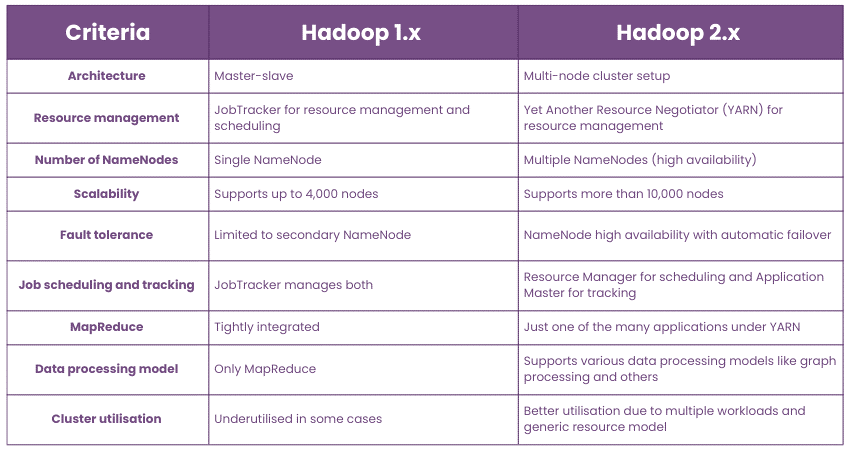
a) Resource management: Hadoop 1.x used JobTracker and TaskTracker for job scheduling and task execution. Hadoop 2.x introduced YARN for resource management, improving scalability and flexibility.
b) Processing model: While Hadoop 1.x only supported the MapReduce processing model, 2.x, with the advent of YARN, can support other processing models as well.
c) Scalability: Hadoop 2.x can support thousands more nodes than Hadoop 1.x, making it much more scalable.
d) High availability: Hadoop 2.x introduced high availability features for the HDFS NameNode, reducing single points of failure.
What is Data locality in Hadoop?
Answer: Data locality refers to the ability of Hadoop to move the computation closer to where the data resides rather than moving large amounts of data across the network. It optimises the data processing speed. There are three types of data locality: Node locality (data is on the same node as the computation), Rack locality (data is on the same rack but a different node), and data-centre locality (different rack but within the same data centre).
Looking to master the world of Big Data storage solutions? Our HBase Training is tailored for professionals like you!
Can you describe speculative execution in Hadoop?
Answer: Speculative execution is Hadoop's way of handling slow-running tasks. Sometimes, certain tasks run slower than others due to hardware issues or other problems. It identifies that this disparity might launch a duplicate task on another node. The first task to finish (either the original or the duplicate) is accepted, while the other is killed. This mechanism ensures that a single slow-running task doesn’t bottleneck the entire process.
What are Sequence files in Hadoop?
Answer: Sequence files are flat files in Hadoop that store data in a binary key-value format. They are especially suited for storing intermediate data between Map and Reduce phases. Sequence files can be compressed, which reduces storage space and enhances performance. They support splitting, even when data inside the file is compressed, making them suitable for it's distributed environment.
How does Hadoop's distributed cache work?
Answer: A distributed cache in Hadoop is a service that caches files when a job is executed. Once a file is cached for a specific job, it is available on each DataNod. This is where the map/reduce tasks are running. This mechanism allows very efficient data access. It's often used for sharing read-only files that are needed by multiple maps or reduces tasks, like configuration files or dictionaries.
How does the Hadoop framework handle data skew in MapReduce?
Answer: Hadoop provides several options to handle data skew, including:
a) Custom Partitioning: To distribute skewed keys more evenly across reducers.
b) Using a Composite Key: Combining skewed keys with other keys to create a composite key can help in distributing the load more evenly.
c) Sampling: Running a sampling job before the actual job to understand data distribution and then using this information for more effective partitioning.
Advanced Big Data Hadoop Interview Questions
These advanced interview questions emphasise the vastness of Hadoop's ecosystem and the critical considerations in implementing and managing it. Read these questions to know how to answer the advanced questions.
How does the Hadoop framework handle data skewing during a MapReduce job?
Answer: Data skewing happens when one node does significantly more work than others due to uneven data distribution. It handles this by:
a) Using the combine phase reduces data volume before it reaches the Reduce phase
b) Sampling input data before job execution to get an idea of key distribution and then partitioning the keys accordingly
c) Implementing a custom partitioner to ensure a more even distribution of data
Can you explain the difference between HBase and Hive?
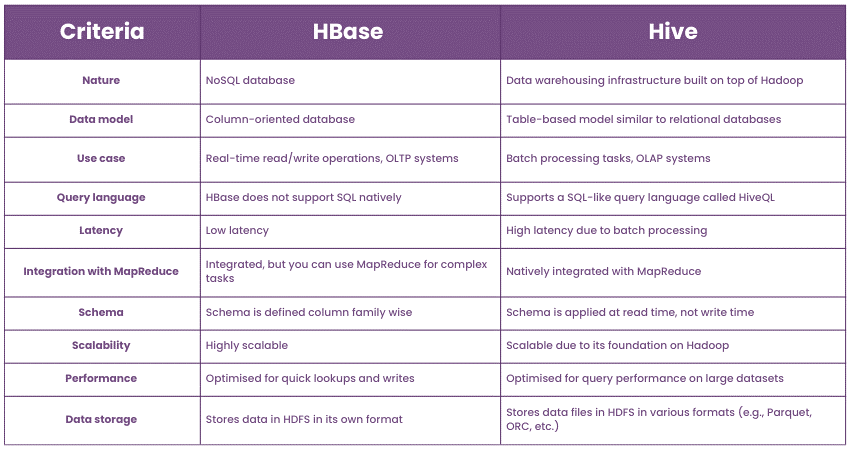
a) HBase: It is a distributed, scalable, and NoSQL database that runs on top of HDFS. It's modelled after Google's BigTable. It is also used for real-time read/write access to large datasets.
b) Hive: A data warehouse infrastructure that is built on top of Hadoop. It provides an SQL-like language called HiveQL for querying stored data. Hive is best for batch processing and isn't designed for real-time queries.
Are you ready to become a leader in the data-driven future? Unlock unparalleled career opportunities with our Advanced Data Analytics Certification course.
What configuration parameters would you tweak when setting up a Hadoop cluster for optimal performance?
Answer: Some critical parameters are:
a) dfs.block.size: To set the size of blocks in HDFS. Larger block sizes can reduce the amount of metadata stored on the NameNode.
b) mapreduce.job.reduces: To set the number of reduce tasks.
c) io.sort.mb: To set the buffer size for sorting files.
d) mapreduce.task.io.sort.factor: Controls the number of streams that merges at once while sorting files.
Describe how Hadoop ensures data recovery in case a node fails?
Answer: Hadoop ensures data recovery through:
a) Data replication: It replicates each data block (by default, three times) across different nodes. If one node fails, data can be retrieved from another node holding a replica.
b) Heartbeat signals: DataNodes send heartbeats to the NameNode. If a node fails to send a heartbeat, it's considered faulty, and the data is replicated elsewhere.
How does Hadoop provide security for its stored data?
Answer: Hadoop uses several mechanisms for security:
a) Kerberos authentication: Ensures that users and services are verified.
b) HDFS file permissions: Similar to Unix permissions, it governs who can read or write to files.
c) Encryption: It can encrypt data at rest in HDFS and data in transit during a MapReduce job.
d) Apache knox and ranger: Tools that provide additional security features like firewalls and access control.
Eager to become a key player in the intersection of Big Data Analytics and Data Science? Our Big Data Analytics & Data Science Integration Course is the perfect stepping stone for you.
Explain the significance of the Hadoop's 'Reducer NONE' pattern.
Answer: When set to 'Reducer NONE', the MapReduce job has no reduce phase. Only the map tasks execute, which may be useful when raw outputs from the map phase are required without any aggregation or further processing. This approach can speed up jobs when a reduce step is unnecessary.
How can you optimise the Hadoop MapReduce job?
Answer: Keep the following points in mind to optimise the Hadoop MapReduce job:
a) Use combiners: Wherever applicable, using a combiner will reduce the data sent to the reducer.
b) Optimise with appropriate data types: Using appropriate Hadoop Data Types can reduce storage and serialisation/deserialisation costs.
c) Increase the number of reducers: More reducers can lead to faster processing, but the ideal number needs to be configured based on data size.
d) Tune framework parameters: Adjusting parameters like io.sort.mb and io.file.buffer.size can help in performance optimisation.
Can you explain speculative execution in the context of data reliability and node failures?
Answer: Speculative execution in Hadoop handles scenarios where tasks take unusually long to complete. It is not just because of data skewing but also due to possible node inefficiencies or failures. It might predict that a task (either Map or Reduce) will take longer than other similar tasks. In response, it launches duplicate tasks on other nodes. Whichever task finishes first is accepted, ensuring a possible node failure doesn’t stall the entire job.
Discuss the role of ZooKeeper in a Hadoop ecosystem.
Answer: Apache ZooKeeper is a centralised service for maintaining configuration information, naming, and distributing synchronisation and group services. In the Hadoop ecosystem, it's critical for high availability and fault tolerance. Services like HBase and Kafka rely on ZooKeeper to manage distributed tasks, like ensuring that there's only one active master.
Can you explain the differences between HDFS Federation and HDFS High Availability?
Answer: In HDFS Federation, multiple namespaces and namenodes are supported, without any overlapping among them. Each namenode manages its own namespace and does not interfere with other namenodes. This improves scalability and isolation.
HDFS High Availability is designed to eliminate the single point of failure in HDFS by providing multiple namenodes in an active-standby configuration. Zookeeper is often used to manage this configuration and ensure automatic failover.
Learn how to easily connect, manage, and transform disparate data sources into actionable insights using Talend's robust platform with our Data Integration And Big Data Using Talend course.
 If you wish to make any changes to your course, please
If you wish to make any changes to your course, please


